NLP Web App with Streamlit
A simple step-by-step guide for building natural language processing application.


Introduction
This simple Natural Language Processing web-app can be built in few minutes and with few lines of codes using Streamlit. The app can be used to perform NLP task like tokenization, translation, summarization, n-gram, et cetera.
Streamlit has made it easy and simple for newbie in data science and machine learning to deploy models and build web-app without having to go through more sophisticated web framework like Django and Flask. It is the fastest way to build and share data apps as it turns data scripts into sharable web apps in minutes.
If you are new to Streamlit and would like to explore further, check their official documentation here
What is Natural Language Processing ?
Natural Language Processing, or NLP for short, is broadly defined as the automatic manipulation of natural language, like speech and text, by software. It is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data.
The study of natural language processing has been around for more than 50 years and grew out of the field of linguistics with the rise of computers.
Let's get started to build NLP app...
The steps involved in building the app are:
Step 1: Install dependencies
Step 2: Import necessary packages
Step 3: Re-modify UI from default setting
Step 4: Write the main script
The whole lines of codes is available via the GitHub repository link here.
Step 1: Install dependencies
In order to build our NLP app, we need to install all necessary packages that we would use for tokenization, translation, summarisation etc.
It can be installed via your terminal, Anaconda prompt(with an administrator permission) and also directly from jupyter notebook.
Install as shown below (I used Anaconda prompt).
pip install streamlit
pip install pandas
pip install matplotlib
pip install seaborn
pip install nltk
pip install textblob
pip install gensim
pip install summa
Step 2: Import necessary packages
After proper installation of all dependencies, we would open our text editor (I used Sublime here ) and create a python file where all codes will be written and later run as script.
Now, import all the necessary packages required to get this app running....
import streamlit as st
st.set_option('deprecation.showPyplotGlobalUse', False)
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('Agg')
import seaborn as sns
sns.set_style('darkgrid')
import nltk
import textblob
from textblob import TextBlob
from nltk import ngrams
from nltk.corpus import stopwords
from nltk.sentiment import SentimentIntensityAnalyzer
from gensim.summarization import summarize
from summa.summarizer import summarize
From the code snippet above, streamlit which is the main package we are going to use is first installed while other packages like matplotlib and seaborn for visualization are also installed.
Comprehensive Natural Language Toolkit (nltk), textblob and other libraries which perform the main NLP functions are also installed.
Step 3: Re-modify UI from default setting
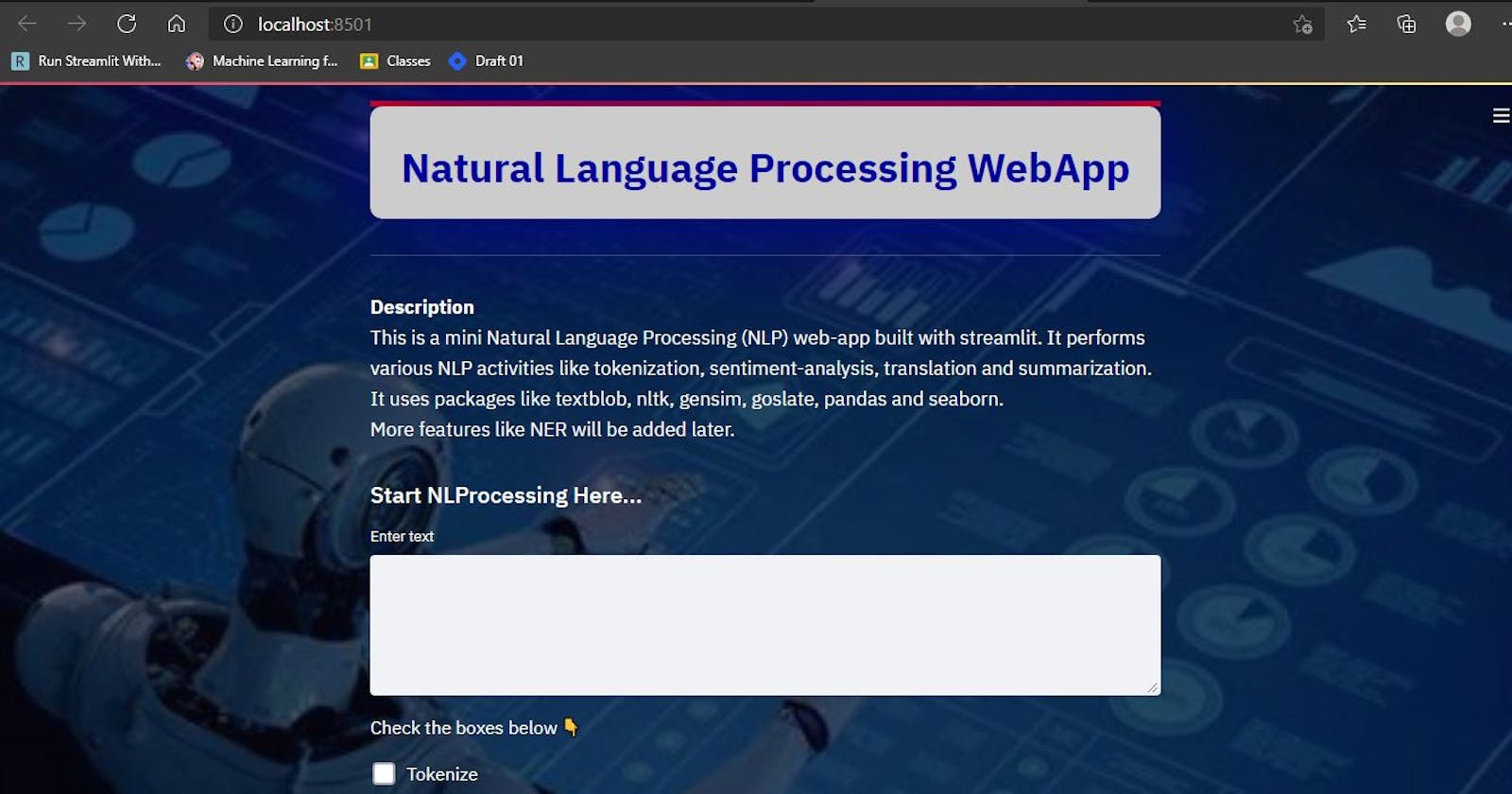
The next step is to reset the background image, font style and size, color for the web app. The title, description and other text are formatted using streamlit markdown function which allow the use of html parsing. This is optional as the default styles could be used.
Python function that allow the use of Image from your local folder to be set as background image is written below:
import base64
@st.cache(allow_output_mutation=True)
def get_base64_of_bin_file(bin_file):
with open(bin_file, 'rb') as f:
data = f.read()
return base64.b64encode(data).decode()
def set_png_as_page_bg(png_file):
bin_str = get_base64_of_bin_file(png_file)
page_bg_img = '''
<style>
body {
color: white;
background-image: url("data:image/png;base64,%s");
background-size: cover;
background-color: white;
-webkit-tap-highlight-color: red;
-webkit-highlight-color: red;
}
</style>
''' % bin_str
st.markdown(page_bg_img, unsafe_allow_html=True)
return
# paste the image file name to reset your background image
set_png_as_page_bg('ai_bkgrd.jpg')
The title and description are also formatted below:
html_temp = """
<div style="background-color:{};height:{};width:{};">
</div>
<div id="head" style="background-color:{};padding:10px;">
<h1 style="color:{};text-align:center;">Natural Language Processing WebApp </h1>
</div>
"""
st.markdown(html_temp.format('red','5px', '100%','#cccccc','#0000A0'),unsafe_allow_html=True)
html_temp2 = """
<hr>
<p id="para" style="font-size:{};color:{};text-align:left;">
<b> Description </b> <br/>
This is a mini Natural Language Processing (NLP) web-app built with streamlit. It performs
various NLP activities like tokenization, sentiment-analysis, translation and summarization. \
It uses packages like textblob, nltk, gensim, goslate, pandas and seaborn.<br/>
More features like NER will be added later.
</p>
"""
st.markdown(html_temp2.format('17px', '#ffffff' ),unsafe_allow_html=True)
Then, we move to:
st.subheader("""
Start NLProcessing Here...
""")
Step 4: Write the main script
Here, we are going to write the main script of the app.
Start:
def main():
Next lines of codes will all be indented with respect to this function till the end of the script.
Create the text box where user will write text to be analysed and extract meaningful information from, by using streamlit text_area function:
word = st.text_area('Enter text ', height = 120)
text = TextBlob(word)
Then, we create the first function which will be text tokenization making use of streamlit checkbox. The simple code is shown below:
Tokenization
if st.checkbox("Tokenize"):
box = st.selectbox("Select",("Sentences", "Words", "Noun Phrases"))
if box == "Sentences":
token_sen = text.sentences
st.write(f"YOUR TEXT HAS {len(token_sen)} SENTENCE(S).\n")
st.write(f"The sentences are : \n")
for w in token_sen:
st.write(w)
if box == "Words":
box_word = text.words
#removing stop words from wordList
stops = set(stopwords.words('english'))
no_stop = [word for word in box_word if word not in stops]
st.write("YOUR TEXT HAS {} WORD(S).\n".format(len(box_word)))
st.write("YOUR TEXT HAS {} WORD(S), EXCLUDING STOPWORDS.\n".format(len(no_stop)))
st.write("\nThe WordList (excluding stopwords) are : \n")
for word in no_stop:
st.write(word)
if box == "Noun Phrases":
noun_ph = text.noun_phrases
st.write("YOUR TEXT HAS {} NOUN PHRASES(S).\n".format(len(noun_ph)))
st.write("The noun phrases are :")
for phrase in noun_ph:
st.write(phrase)
Part-of-speech tagging
if st.checkbox("POS Tagging"):
box = st.selectbox("Select", ("Singular Verb","Proper Noun","Adjective"))
p_word = text.words
stops = set(stopwords.words('english'))
no_stop = [word for word in p_word if word not in stops]
tagged = nltk.pos_tag(no_stop)
if box == "Singular Verb":
st.write('SINGULAR VERBS EXTRACTED :\n')
for word, tag in tagged:
if tag == 'VBZ':
st.write(word)
if box == "Proper Noun":
st.write('PROPER NOUNS EXTRACTED :\n')
for word, tag in tagged:
if tag == 'NNP':
st.write(word)
if box == "Adjective":
st.write('ADJECTIVES EXTRACTED :\n')
for word, tag in tagged:
if tag == 'JJ':
st.write(word)
Translation
lang_dict = {'French':'fr','Afrikaans':'af', 'Irish':'ga','Albanian':'sq','Italian':'it','Arabic':'ar','Japanese':'ja',
'Azerbaijani':'az','Basque':'eu','Korean':'ko','Bengali':'bn','Latin':'la','Belarusian':'be',
'Latvian':'lv','Bulgarian':'bg','Lithuanian':'lt','Catalan':'ca','Macedonian':'mk',
'Chinese Simplified':'zh-CN','Malay':'ms','Chinese Traditional':'zh-TW','Maltese':'mt','Croatian':'hr',
'Norwegian':'no','Czech':'cs','Persian':'fa','Danish':'da','Polish':'pl','Dutch':'nl','Portuguese':'pt',
'Romanian':'ro','Esperanto':'eo','Russian':'ru','Estonian':'et','Serbian':'sr','Filipino':'tl',
'Slovak':'sk','Finnish':'fi','Slovenian':'sl','Spanish':'es','Galician':'gl',
'Swahili':'sw','Georgian':'ka','Swedish':'sv','German':'de','Tamil':'ta','Greek':'el','Telugu':'te',
'Gujarati':'gu','Thai':'th','Haitian Creole':'ht','Turkish':'tr','Hebrew':'iw','Ukrainian':'uk',
'Hindi':'hi','Urdu':'ur','Hungarian':'hu','Vietnamese':'vi','Icelandic':'is','Welsh':'cy','Indonesian':'id',
'Yiddish':'yi'}
#word translation
if st.checkbox('Translate'):
try:
lang = list(lang_dict.keys())
activity = st.selectbox("Language", lang)
trans = text.translate(to=lang_dict[activity])
st.write(trans)
except:
st.markdown('*Error, check your text!*')
Sentiment analysis
#sentiment analysis using SentimentIntensityAnalyzer
if st.checkbox("Sentiment Analysis"):
try:
sia = SentimentIntensityAnalyzer()
sent_claf = sia.polarity_scores(str(text))
if sent_claf['pos'] > 0.5:
st.write(f"Positive Review: {round(sent_claf['pos']*100)}%")
elif sent_claf['neg'] > 0.5:
st.write(f"Negative Review: {round(sent_claf['neg']*100)}%")
else:
st.write('Neutral Review')
except:
st.markdown('*Error, check your text!*')
Summarisation
#summarization using Summa & Gensim
if st.checkbox("Summarise"):
try:
if st.button('Gensim'):
from gensim.summarization import summarize
st.write(f"The summary using gensim:\n\n {summarize(str(text))}")
if st.button('Summa'):
from summa.summarizer import summarize
st.write(f"The summary using summa:\n\n {summarize(str(text))}\n")
st.markdown("**No major difference between Gensim and Summa!**")
except:
st.markdown('*Input must be more than one sentence!*')
n grams
#n-grams using nltk
if st.checkbox('Display n-grams'):
try:
sentence = text.words
n_gram = st.number_input('Enter the number of grams: ', 2, )
grams = ngrams(sentence, n_gram)
for gram in grams:
st.write(gram)
except:
st.markdown('*Error, check your text!*')
Word count and frequency visualization
try:
if st.checkbox('Specific Word Count'):
word = st.text_input("Enter the word you'll like to count from your text.").lower()
occur = text.word_counts[word]
st.write('The word " {} " appears {} time(s) in the text .'.format((word),(occur)))
if st.checkbox("Word Frequency Visualization"):
input_no = st.number_input("Enter no of words:", 3,20)
items = text.word_counts.items()
stops = set(stopwords.words('english'))
items = [item for item in items if item[0] not in stops]
from operator import itemgetter
sorted_items = sorted(items, key=itemgetter(1), reverse=True)
top = sorted_items[0:int(round(input_no, 0))]
st.subheader(f"Top {str(input_no)} Words ")
df = pd.DataFrame(top, columns=['Text', 'Count'])
st.dataframe(df)
#display the visualized word frequency
if st.button("Display"):
df.plot.bar(x='Text', y='Count', legend=True)
plt.title("Word Frequency Visualization")
st.pyplot()
except:
st.markdown('*Oops, check your text!*')
End the script here
if __name__ == '__main__':
main()
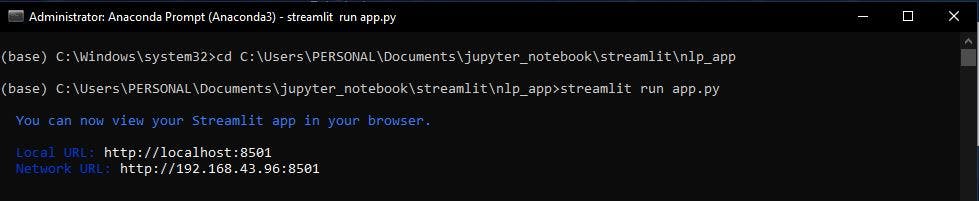
Save the file and run it as script locally as shown below.
Conclusion
In conclusion, with this simple approach we have created a robust app that can be used to analyse text and extract meaningful NLP insight from it.
In the next article, we would go through the deployment of web-app to free hosting platform like heroku.
You can access the live app here